|
|
Frenzo is an instant messaging application with a WML interface. It became more popular than we had predicted and the server could not support the load. Because the server was designed to rely on an in-memory cache for performance, it could not be deployed on a load balanced cluster of nodes without the caches becoming inconsistent. We found that although response time depended on using the cache, throughput did not. We redesigned the server so that each web request’s dirty data was flushed after the request completed. This allowed us to meet the increasing load by deploying the server on a cluster of nodes backed by a shared database.
Frenzo is an instant messaging application with a WML interface. It is a recent fork of an existing product which has been running well for a few years. Frenzo is aimed at a new user base.
Soon after we deployed Frenzo we found that it was more popular than we had predicted and it could not support the load. The CPU and memory usage were close to their limits. This article describes how we redesigned the system to meet its demand.
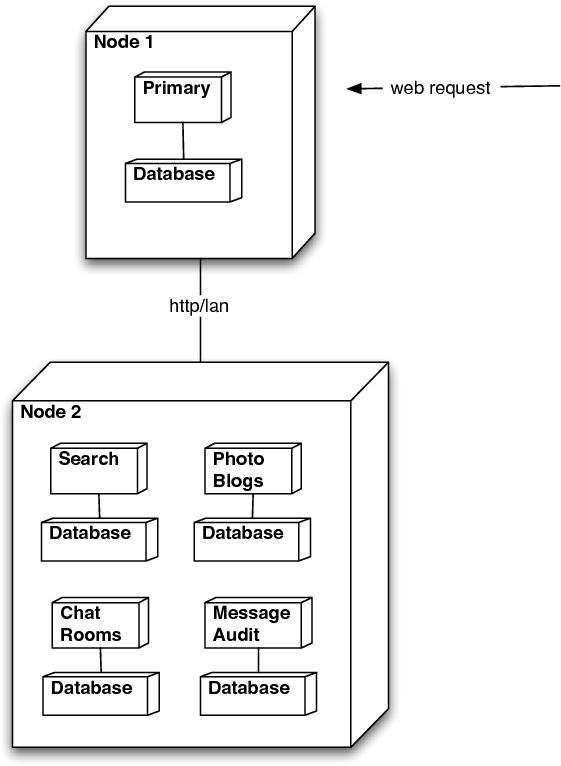
Frenzo consists of a number of distributed components. One of them, known as Primary, is the public interface. Primary uses the other components for various services. Each component has its own data structures and database (Figure 1).
Each component has a similar design for database access. Our focus is Primary. It has a single database connection which is shared by all web request threads. The database transaction runs for minutes at a time and is committed periodically by a separate process. Although this design allows many requests to be served out of the Versant database’s client cache, it prevents us from being able to add more nodes to handle a higher load because the caches on different nodes would get out of synchronization. Another problem with this design is that each commit stalls all request threads for about ten seconds until it completes. This stall affects the user experience and the increasing CPU load during the stall threatens to crash the program.
We had designed the system for conditions of low usage. It was optimised for response time. However, under high load response time was not as important as scalability. The question was which tier of our application did we need to scale up? In the past we had assumed that the database server was limiting us. We had tried various methods of scaling it up, such as partitioning the database into smaller databases, and distributing Frenzo into components. However, reports from our production system now indicated that it was the application server’s CPU and memory which were reaching their limits during peak hours. If it was the application server that was limiting scalability, and not the database, then we were concentrating on the wrong tier.
We decided on the following three steps:
The first step was to add Resin [1] support to the Java Interactive Profiler (JIP) [2] and then examine the profile of a couple of web requests to Frenzo. We wrote Awk scripts to bring the profile data into a PostgreSQL database which then allowed us to use SQL to examine the profile in various ways. There were three useful queries. The first ranked methods by net time spent. In JIP terminology the net time spent in a method is the total time spent in the method less the total time spent in child methods that that method calls. It gives an idea of the work done by a method itself. The second SQL query ranked methods by invocation count. The third query ranked them by the sum of the first two rankings. We scanned through the first forty results of each query output and picked a total of approximately fifteen items to optimize.
We optimised Primary by removing logging from inner loops, caching encryption and decryption results, and caching instances of classes which needed computations such as string parsing during their construction. The profile result also pointed to excessive object instantiation. To reduce this, we changed a few completely stateless classes so that they contained static methods instead of instance methods. A load testing program we developed showed that all our optimisation increased the throughput capacity by roughly thirty percent. This was good, but it wasn’t good enough.
There are two ways in which Primary makes remote HTTP calls to secondary components. One is by making a call inline in the code. The other is by triggering an event and letting an EventManager make the call. It is hard to roll back the effect of these remote calls should Primary’s database transaction eventually roll back. We changed the EventManager to place events on a thread local queue. This queue would only be processed after the database transaction had completed. So conceptually there were now two parts to a web request’s transaction — the database part and the event part.
We decided not to worry about the remote calls which were made inline in the code, since we knew there were only a few. We also decided to ignore the possibility of remote calls failing. Later, we would probably integrate the secondary components into Primary anyway.
The profiler showed that the remote calls Primary made to secondary components took a significant proportion of the request processing time. In addition to making them clusterable, integrating the secondary components into Primary would let us do away with remote calls between components.
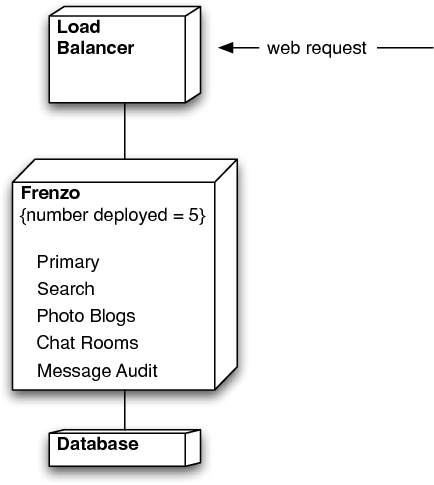
For each component, remote HTTP calls to that component were changed into local method calls. Since components would now share a database with other components, we also had to add namespaces to the data lookup keys to avoid conflicts.
Once the integration was complete, we reverted Primary’s event handling design to not enqueue events, but instead to handle them immediately as before.
One consequence of concurrent database transactions is deadlocks. With the new design, we observed a deadlock approximately every fifty web requests. We had two concerns about this —data integrity and usability.
Our database system detects deadlocks and raises a runtime exception in the deadlocked request thread. However it does not invalidate the transaction, which is allowed to continue and commit later. This was a problem for us because in some places the middle layer of our code would catch all exceptions, including runtime exceptions, and silently ignore them. If now a deadlock exception were caught and silently ignored, the transaction might commit inconsistent data. We worked our way up through the code, starting from the persistence layer, making sure that deadlock exceptions were not caught unintentionally, and that if they occurred they would propagate all the way up to the servlet, which was looking for them and would roll back the entire transaction.
When a transaction is rolled back due to a deadlock then the user is shown an error message and is expected to retry the operation. The large number of deadlocks and error messages made for poor usability. In order to address this, we worked our way through the various locations in our code where deadlocks occurred, starting with the most frequent occurrences. In each instance we considered a number of options.
In the first instance of deadlocks we had a setter method whose implementation would test an array of old values before overwriting them. Changing the implementation to acquire an exclusive lock even for the read-only testing operation removed the deadlock.
There are deadlock instances, such as one user sending a chat invite to another, which need locks on two User objects. Here we avoided deadlocks by modifying the request handlers to acquire locks in alphabetical order of username [3].
For chatrooms, we experimented with retrying a deadlocked request a small number of times with increasing wait periods between retries. We found that very few transactions that had deadlocked in the first try would succeed in subsequent tries. Perhaps our backoff algorithm needed improvement, or it may have been that our load test was not representative of actual usage. Our solution in this instance was to separate read-only operations from the others and to turn off locking for the read-only operations. We chose to live with the non-repeatable reads this could introduce. For write operations, besides room joining and room leaving operations, message posting could also modify room membership. We made these three operations purely sequential. There is a single “room membership” lock common to all rooms which each of these three operations must acquire before executing. This is good enough for now because chatrooms is not a bottleneck.
Our work so far has reduced the deadlock frequency to one in every five thousand web requests. There is still room for improvement but the program is usable enough to be put into production.
Our implementation had the effect of keeping the throughput of a single application server node roughly the same as before. While it didn’t increase as we had hoped it might, it didn’t decrease and this was important. When the application was deployed on a cluster of four nodes and load tested, it showed four times the throughput in total. The database server’s CPU usage went from 2% with one node to 9% with four nodes.
In production, a few days after Frenzo was deployed on a cluster of five machines, its usage doubled. Had we only installed twice the number of machines, Frenzo might have been less responsive than it was before our redesign because we had removed caching. Since we installed five times the number of machines, it was actually more responsive, and this was a pleasant surprise.
The database server machine is still quite lightly loaded and promises to support ten to fifteen application server nodes before becoming the bottleneck.
Measurements showed that eliminating remote calls by integrating secondary components into Primary sped up request handling by a fifth.
We are rid of the commit stall.
Despite the remaining deadlocks, Frenzo’s new design causes far fewer failed requests than before, so we have decided to keep it.
We have met our usage requirements, and we have a scalable design for the near future. We hope that Frenzo becomes popular enough to reach the limits of this design too. When this happens we will redesign the program again. Perhaps the next time the database will be the bottleneck and a web services architecture will take us to the next level of scalability.
The lesson we have learned is that the real bottleneck is not always where one thinks it is. For years our programmers have been trying to cache data, break the program into smaller components, and think of ways to avoid the roundtrip to the database. This textbook bottleneck wasn’t, in fact, our program’s bottleneck. At our usage load and with our program’s design, the database was a long way away from being the bottleneck. We had to realise this, and then go in the opposite direction — not cache data and integrate previously distributed components into one — to properly scale to the next level. It is very rewarding to learn where the single bottleneck in a program is, when trying to improve its performance.